




Przygotowanie
Ten sam efekt wyjściowy udało się uzyskać za pomocą dwóch głównych zapytań. Pierwsze z nich, to utworzenie dodatkowych kolumn przez adresowanie odpowiednich wierszy łączonej tabeli (rozwiązanie proponowane przez Django ORM). Drugie wykorzystuje funkcję crosstab() bazy danych PostgreSQL, która tworzy pivot wyniku podzapytania i dołącza go jako kolejne kolumny do wyniku. W dalszej części te dwa typy zapytań będą nazywane odpowiednio: original i crosstab.
Ze względu na to, że dane są typu rzadkiego, zdecydowaliśmy się nie trzymać wartości zerowych, przyjmując konwencję, że brak danych to dane o wartości zero.
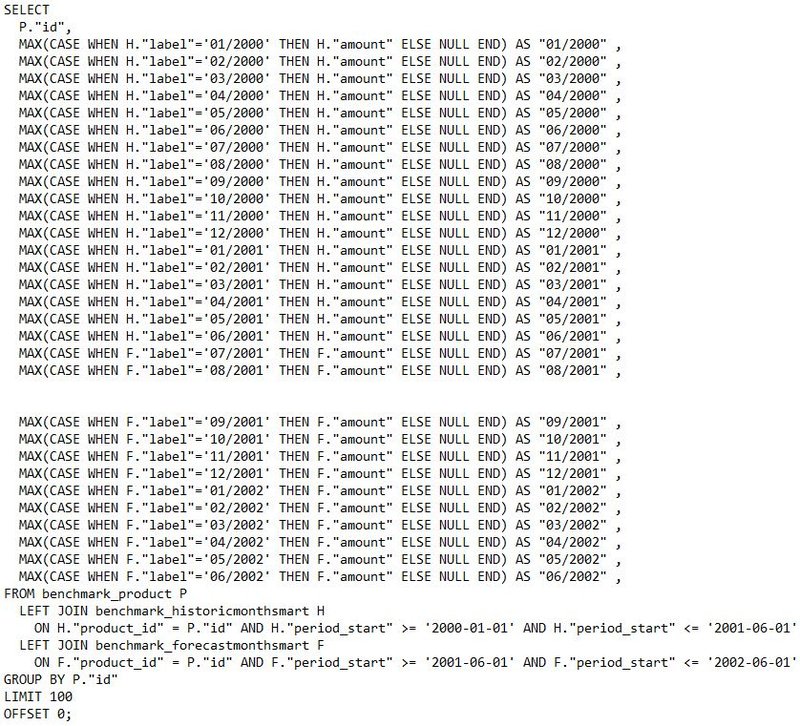
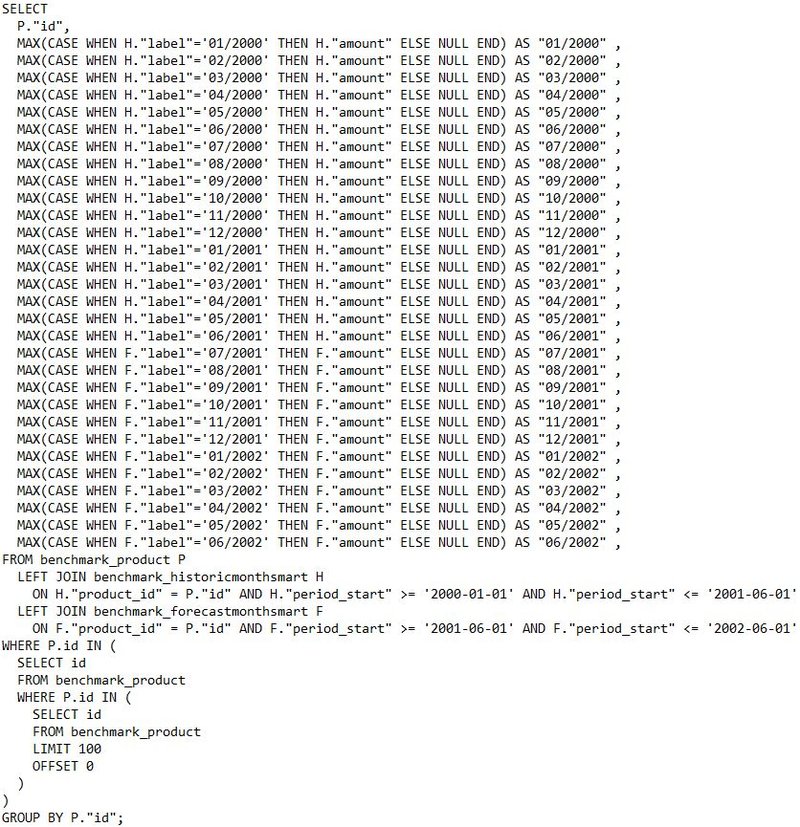
Słuszność tego wyboru także postanowiliśmy przetestować, wobec czego, stworzyliśmy nową bazę produktów (15 tysięcy wartości) i po dwie tabele danych historycznych i prognoz (które są dynamicznie włączane do zapytania o produkty). Pierwszy zestaw, nazwany simple zawiera wiersze z wartościami zarówno zerowymi, jak i niezerowymi. Drugi, nazwany smart, wyłącznie z wartościami niezerowymi. Prawdopodobieństwo wygenerowania danych niezerowych ustaliliśmy na 0.4.
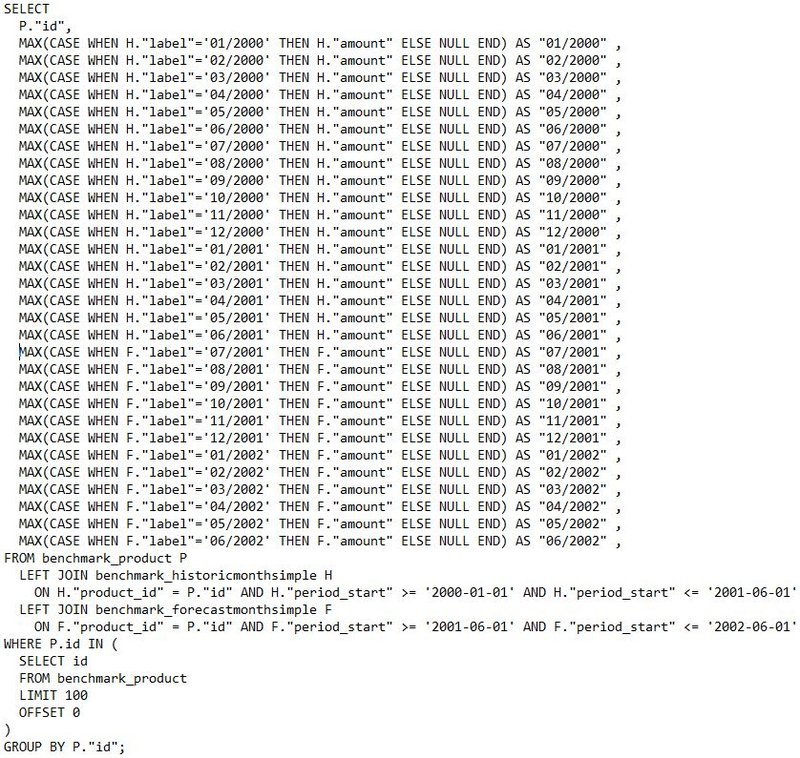
Trzecia ważna optymalizacja, którą została zaimplementowana to zastąpienie klauzuli OFFSET klauzulą WHERE “id” IN () z prostym podzapytaniem o offsetowane id indeksów, które będą przetwarzane przez zapytanie główne.
W ten sposób powstało osiem testowanych zapytań:
- Original Simple Offset
- Original Simple Where
- Original Smart Offset
- Original Smart Where
- Crosstab Simple Offset
- Crosstab Simple Where
- Crosstab Smart Offset
- Crosstab Smart Where
Testowany był czas wykonania zapytania i odczytu danych. Wynikiem jest średnia z 15 zapytań o 100 kolejnych produktów z indeksami co 1000. (Innymi słowy pierwsze zapytanie to produkty o id 1-100, ostatnie o id 14001-14100). Całość została przetestowana w 50 iteracjach za każdym razem dodając po jednej prognozie i jednej wartości historycznej, a pobierając 18 kolumn danych historycznych (ze znalezioną wartością lub 0 jeśli danej wartości nie ma) i 12 kolumn prognoz (za każdym razem zmieniając okres, aby ominąć cache bazy danych). W efekcie pierwsze zapytanie operowało na bazie zawierającej 30 tysięcy wpisów dla trybu simple lub ok. 12 tysięcy dla trybu smart. Ostatnie zapytanie musiało przetworzyć bazę z 1 530 000 wpisów (lub ok. 612 000 dla trybu smart).
Zapytania
Original Simple Offset
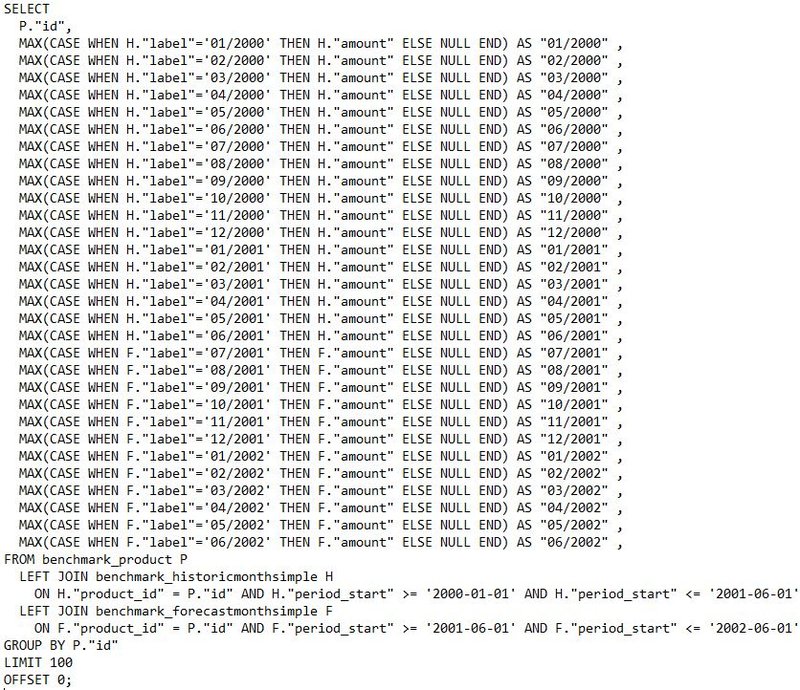
Original Simple Where
Original Smart Offset
Original Smart Where
Crosstab Simple Offset

Crosstab Simple Where

Crosstab Smart Offset

Crosstab Smart Where

Wyniki
Wyniki prezentują się następująco:
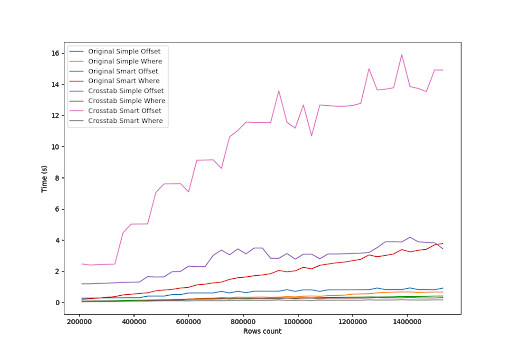
Zapytanie używające funkcji crosstab() i generowane za pomocą klauzuli OFFSET okazało się skrajnie niewydajne zarówno dla bazy zawierającej wiersze z wartością zerową, jak i dla tej, która te wartości omijała. Zapytanie z prostym przyporządkowaniem kolumn poprzez klauzule CASE-WHEN i optymalizowana przez podzapytanie również nie okazałaby się dobrym wyborem, gdyż jej czas wykonywania rośnie diametralnie wraz ze wzrostem wielkości bazy danych i potrzebując około 4 sekund przy 1,5 miliona wierszy w przetwarzanych tabelach.
Po usunięciu najbardziej niewydajnych zapytań, wykres staje się bardziej przejrzysty.
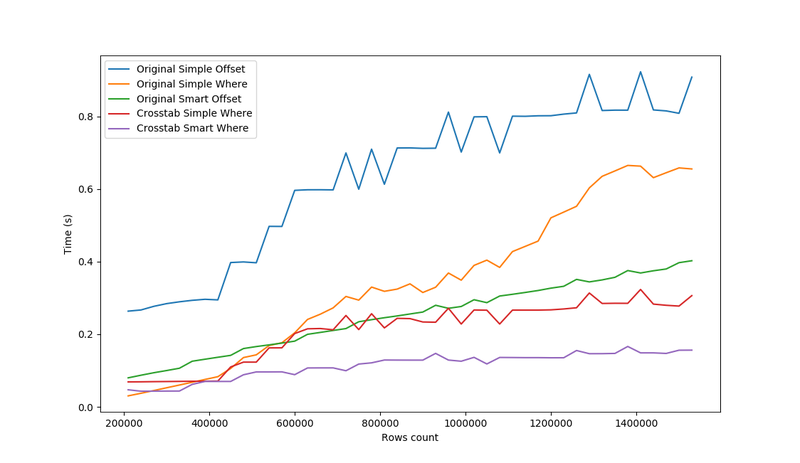
Zastosowana przez nas funkcja crosstab() wraz ze wszystkimi optymalizacjami okazała się najbardziej stabilna i najbardziej wydajna dla rosnącej ilości przetwarzanych danych. Ta sama funkcja, ale przetwarzająca 60% wierszy zawierających główne wartości zerowe okazała, przewidywalnie, gorsza ze względu na większą ilość danych, które musiały być odczytane. Wersja smart lepiej wykorzystuje możliwości funkcji crosstab(), która najpierw tworzy oczekiwany szkielet kolumn z domyślną wartością, a następnie uzupełnia je danymi, jeżeli takie istnieją.
Zapytanie wygenerowane przez DjangoORM zdecydowanie lepiej się sprawdza przy mniejszej bazie danych.
Najbardziej dziwi wręcz skrajna rozbieżność między zapytaniami Original Simple Where i Original Smart Where, gdzie wydawałoby się, że to drugie powinno być znacznie wydajniejsze. Przyczyną tych różnic jest prawdopodobnie sposób przetwarzania klauzuli CASE-WHEN. W przypadku pełnej bazy warunek CASE jest zawsze spełniony, przez co druga część (THEN) już nie jest przetwarzana, co wyraźnie widać w czasie wykonywania zapytania.
Domyślne zapytanie DjangoORM zoptymalizowane przez klauzulę WHERE IN okazało się jednak najbardziej wydajne dla “niewielkiej” ilości danych (do 300 tysięcy przetwarzanych wierszy wykonywało się szybciej niż Crosstab Smart Where, niecałe 3-4 setne sekundy). To samo zapytanie bez optymalizacji potrzebowało już 8 setnych i więcej.
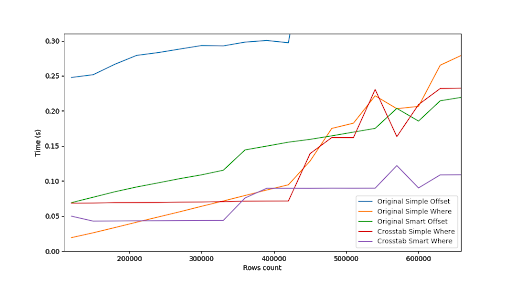
Sytuacja się jednak zmienia powyżej pół miliona wierszy, gdy zapytanie z klauzulą OFFSET okazuje się wydajniejsze.
Podsumowanie
Funkcja crosstab() często może być najlepszym wyborem znacznie przyspieszającym skomplikowane operacje przemapowania wierszy podzapytania na kolumny, ale do wydajnego działania wymaga dość specyficznych warunków: możliwie mało wierszy do przetworzenia i koniecznie ze wskazaniem konkretnych wierszy zamiast wykorzystania klauzuli OFFSET w głównym zapytaniu.
Optymalizacja przez ograniczenie ilości przetwarzanych wierszy też nie zawsze jest najlepszym wyborem, zwłaszcza przy podstawowych zapytaniach, które mogą dobrać wartość przez klauzulę CASE-WHEN, która stosunkowo niewiele obciąża zapytanie, jeżeli zawsze dostępna jest wartość.
Podobnie z optymalizacją przez podzapytanie. Ten wariant optymalizacji sprawdza się szczególnie, gdy zależne zapytanie wykonuje kosztowne operacje, a które są wykonywane podczas przesunięcia OFFSET.











