




We get equal results with two different queries. The first one was to create additional columns with reference to the related rows of the joined table (solution). The second one uses Postgres crosstab() function, which adds a pivoted subquery as new columns. In this article, they will be called original and crosstab respectively.
Due to the fact that the data are a rare type, we decided to skip all the empty rows assuming that no data is the data with zero value.
This also will be checked in this benchmark. We created a database of new products (15.000 values), two historical and two forecast tables. One set, called simple for all rows (empty and with values) and smart which contains only rows with values. We generated data with probability 0.4.
Our third optimisation was to replace OFFSET in the main query with WHERE “id” IN () clause (with OFFSET subquery in the single product table to get set of products' id).
We ended with eight test-queries:
- Original Simple Offset
- Original Simple Where
- Original Smart Offset
- Original Smart Where
- Crosstab Simple Offset
- Crosstab Simple Where
- Crosstab Smart Offset
- Crosstab Smart Where
We tested the query and reading execution time. The result the mean of 15 queries about 100 products with an offset of 1000 (in other words: the first query is about products with id 1-100, the last query is about products with id 14001-14100). It was tested in 50 iterations, each time with one additional forecast and one additional historical value, and obtaining 18 columns with the historical data (with value or 0 if there is none) and 12 columns with the forecasts, always with a different date (to avoid Postgres caching). As a result, the first query needed to process 30.000 entries (simple, and ca 12.000 in smart mode), and the last one - 1.530.000 entries (ca 612.000 in smart mode).
Queries
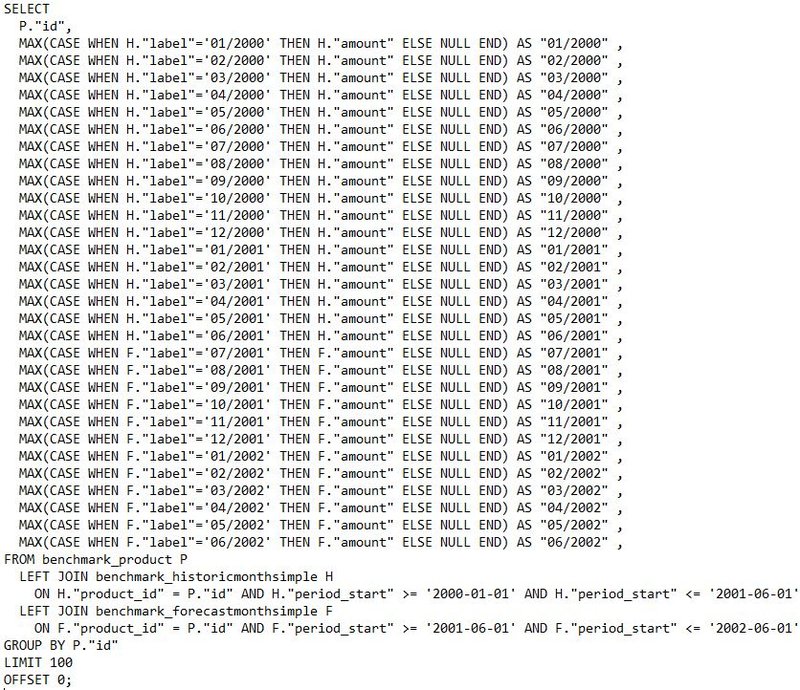
Original Simple Offset
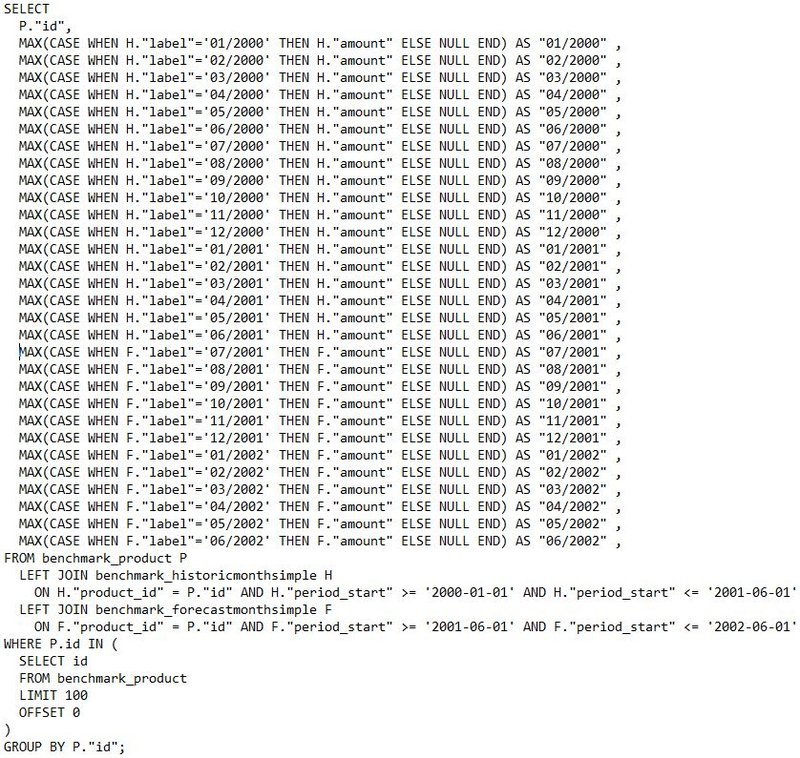
Original Simple Where
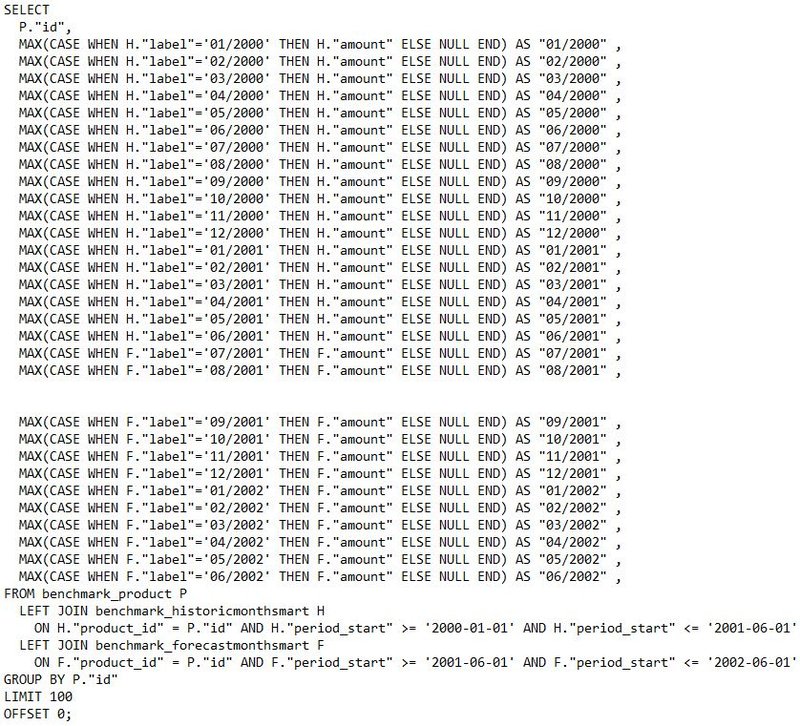
Original Smart Offset
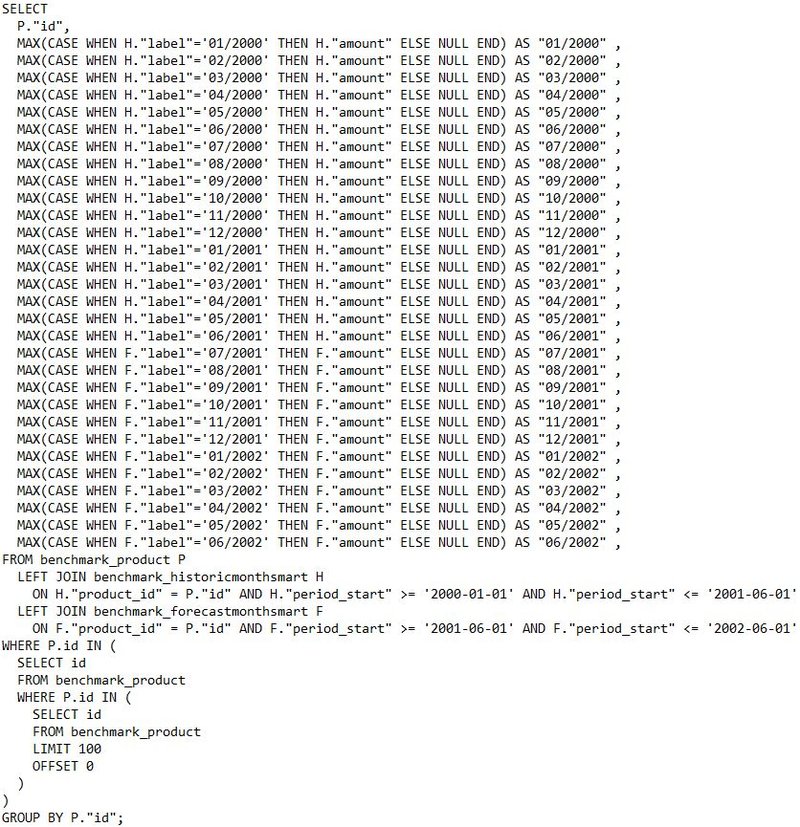
Original Smart Where
Crosstab Simple Offset

Crosstab Simple Where

Crosstab Smart Offset

Crosstab Smart Where

Results look as follows:
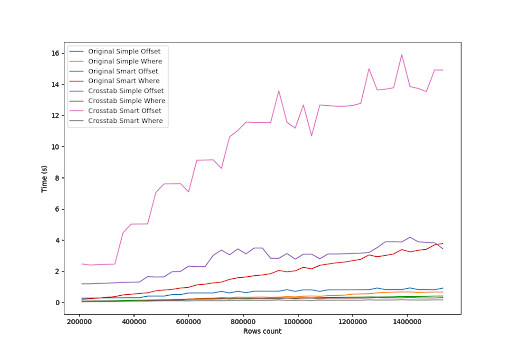
Both crosstab() queries with OFFSET were very ineffective, no matter if there were empty rows or not. The query with simple mapping columns and WHERE was very ineffective for a larger amount of data as well. 1.5 million of rows were processed in over 4 seconds.
Removing these three queries make the chart more readable:
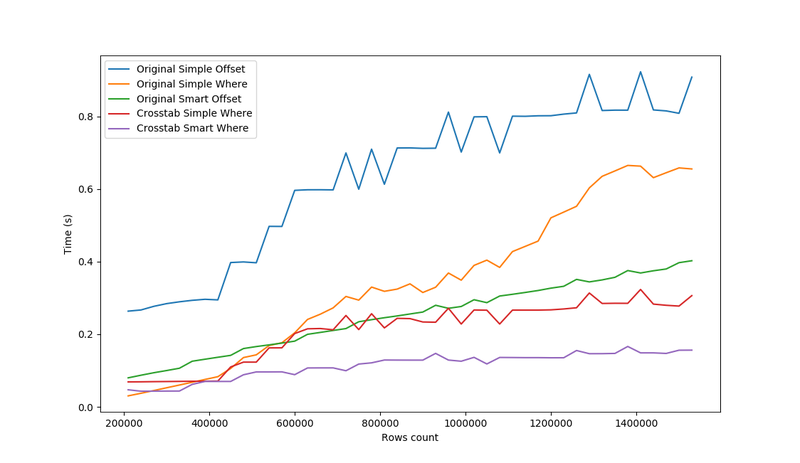
The crosstab() function, which we decided to use in our application with all our appeared the most stable and the most efficient for the growing number of the processed data. If this function needed to process empty rows, it would have a noticeably worse performance. The Smart version uses the advantages of the crosstab() function in a better way, which creates the expected columns skeleton with default values and fulfills it with the data if there is any.
However, the query is really a better solution with a smaller amount of data.
The biggest surprise from these results is a very big difference between Original Simple Where and Original Smart Where queries, where it would seem, that this second one should be more efficient. The reason for that is probably how the CASE-WHEN clause is processed. For the whole database, the first condition of is always fulfilled and the THEN part isn’t processed at all, which is clearly visible in the query execution time.
On the other hand, the default query with WHERE IN is more efficient for a 'small' amount of the processed data (a query with up to 300 k rows executes in 30-40 milliseconds). An equal query without WHERE IN takes 80 milliseconds and more to finish.
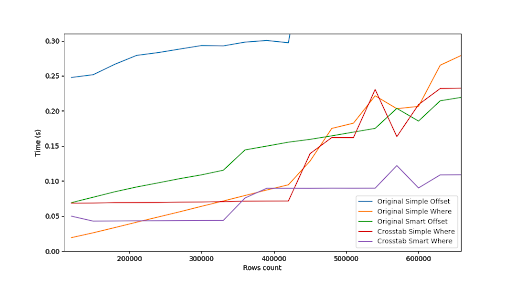
But for over 500.000 processed rows OFFSET query has better performance.
Summary
There is no golden rule.
The crosstab() function in some specific conditions can be a better solution for complicated pivot operations. For better performance, there must be as few processed rows as possible and we should avoid using the OFFSET clause.
Optimisation by removing rows with some default data is not always the best solution either. All default (CASE-WHEN) queries work better when there are destination rows.
A subquery is a similar story. This type of succeeds especially when the main query uses costly computation functions. For all simpler solutions, OFFSET works better than an additional subquery.











